今やChat GPTについて知らない人はいないんじゃないか?って思えるぐらい有名になりました。しかし、何でこんな物が突然現れたのか不思議に思う方も多いのではないでしょうか?そこで、Chat GPTが登場するまでの様々な技術について、数式は使わずに平易に解説していくシリーズとして「Chat GPT はどうやって生まれてきたのか?」を連載しています。今回はその8回目となります。前回に引き続き Transformer について説明していきます。
この連載の第5~7回で、Chat GPT の GPT は Generative Pre-trained Transformer の略であることと、Transformer は、自然言語処理で利用されるモデルの名前で、元々は機械翻訳のために作られたものであることをお伝えしました。第7回では、Transformer の概要,Transformer の構成,Transformer の Attention について説明しました。ここでは、Transformer について引き続き説明していきます。
なお、Transformer の発表論文を以下に再掲しておきます。
1.1 Transformer における Multi-Head Attention の使用
第7回において、従来の seq2seq + attention モデルの RNN 部分を attention に置き換えることによって、Transformer が登場したと書きました。また Transformer Encoder 内の Multi-Head Attention は、seq2seq + attention の Encoder(RNN) に、Transformer Decoder 内の Multi-Head Attention は、seq2seq + attention の attention に、Masked Multi-Head Attention は、seq2seq + attention の Decoder(RNN)に、それぞれ対応していると説明しました(図1)。
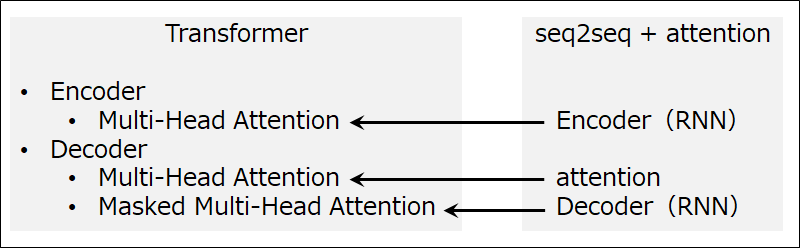
Multi-Head Attention は、RNN の代替と従来の attention (どの単語に注目すべきかを学習する)のどちらでも利用できるようになっています。なお、Masked Multi-Head Attention は、一部の参照をマスク(無効化)する機能を追加しただけで、基本的には Multi-Head Attention と同じです。
以降では、それぞれの目的に対する Multi-Head Attention の使用について説明します。なお、説明にあたって、翻訳する元の言語をソース言語、翻訳先の言語をターゲット言語と呼ぶことにします。
Encoder(RNN)や Decoder(RNN)の代替として

seq2seq + attention モデルの Encoder(RNN)や Decoder(RNN)の代替として利用する場合は、Q,K,Vに全て同じものを入力します(図2)。これは、self-attention と呼ばれます。self-attention により、系列内の単語どうしの関係を把握できるようになります。 なお、Q,K,Vに同じものが入力されても、Multi-Head Attention 内に入れば直ぐに、それぞれ変換されます。変換パラメータはQ,K,Vそれぞれで違うだけではなく、ヘッド毎にも異なります。Multi-Head Attention は、これらの変換パラメータを学習により調整します。
attention(どの単語に注目すべきかを学習する) として

seq2seq + attention モデルにおける attention のように、翻訳時にどの単語に注目すべきかを学習する場合は、Qはターゲット言語側から、V,Kはソース言語側から入力します(図3)。これは、source-target attention と呼ばれます。
本連載の第6回では RNNsearch の alignment について説明し、これが attention の元ネタと紹介しました。RNNsearch のときと目的(どの単語に注目すべきかを学習する)は同じですが、学習方法は異なりますので注意してください。
これで Transformer の3つの主要部品を Multi-Head Attention または Masked Multi-Head Attention で構成できました。主要部品のみの Transformer 全体構成図を図4(左)に、論文掲載の構成図を図4(右)に示します。論文掲載図では Multi-Head Attention への入力の Q,K,V が省略されており、接続が分かりづらいですが、図4(左)を参照すれば理解の助けになると思います。

1.2 Transformer の動作
Transformer の動作は、従来の seq2seq と基本的には同様です。違いは、RNN が attention に置き換えられているため、単語系列を1単語づつに分けて入力する必要がなく、一度に入力することができる点にあります。但し、予測時(翻訳するとき)の Decoder は、従来動作に近い回帰的な動作になります。これは、 seq2seq のときと同様に、Decoder がそれまでの単語系列から次の単語を予測するモデルを構築しているからです。つまり、単語系列を入力すると、その単語系列に次の単語を追加した単語系列を出力します。これを繰り返すことによって翻訳文を生成します。
なお、上記のように、Decoder がそれまでの単語系列から次の単語を予測するときに、予測すべき単語より後ろを参照するのはおかしいので、その部分をマスク(無効化)するようにしたのが、Masked Multi-Head Attention です。
2. おわりに
第7回から引き続き Transformer について説明しました。このように、Transformer はニューラルネットワークを使った機械翻訳用のモデルとして登場しました。しかしながら、Transformer は非常に高速で高性能だったため、機械翻訳だけではなくその他の様々な用途で使われるようになっていきます。次回は、Transformer を使用した GPT と BERT についてお届けする予定です。